
We've all been there. Staring at a PDF packed with valuable data, knowing you need it in Excel, but the simple copy-paste just mangles everything. It's a universal frustration. The root of the problem is that PDFs were designed to be the digital equivalent of paper—they prioritize a fixed, consistent look over easy data access.
Why Is Getting Data Out of a PDF So Hard?
At its core, the PDF format itself is the biggest hurdle. When Adobe created the PDF, the goal was to make a document that looked exactly the same no matter what computer or operating system opened it. It was a brilliant solution for sharing formatted documents, but it was never meant to be a database or a spreadsheet.
This means the data inside isn't structured in a way computers can easily understand. Think about a standard invoice. To our eyes, it's a perfectly organized layout with customer info, a list of items, and a grand total. But to a computer, it's often just a jumble of text fragments and lines positioned at specific coordinates. There's usually no built-in logic that says, "Hey, this price belongs to that line item."
Native vs. Scanned PDFs: A Tale of Two Files
The challenge gets even trickier when you realize you're dealing with two very different kinds of PDFs.
-
Native PDFs: These are the "good" ones, at least relatively speaking. They're created directly from software like Microsoft Word or an accounting program. The text inside is real, which means you can select, copy, and search it. While they are far easier to work with, the data can still be fragmented or formatted in ways that don't play nice with spreadsheets.
-
Scanned PDFs: These are the real headaches. A scanned PDF is essentially just a picture of a paper document. The "text" you see is part of an image, not actual text characters. You can't select or copy it. To get anything useful from these files, you first need to run them through a process called Optical Character Recognition (OCR), which scans the image and converts the shapes of the letters into machine-readable text.
The real challenge isn't just yanking text out of a PDF. It's about preserving the structure—the relationships between the different pieces of data. Without that context, a column of numbers is just a column of numbers, useless for any real analysis.
The Real-World Cost of Doing It by Hand
Relying on manual copy-pasting or, even worse, retyping data from a PDF into Excel isn't just slow—it's a massive drain on resources. I’ve seen it firsthand. It opens the door to a terrifying number of human errors. A single misplaced decimal or a typo in an invoice number can lead to serious accounting headaches down the line.
For any business that handles hundreds of documents a month—think bank statements, purchase orders, or financial reports—this manual grind becomes a huge operational bottleneck. It delays critical analysis and slows down decision-making. If this sounds familiar, our detailed guide on how to convert PDF to CSV can offer a much smoother path.
This is exactly why the demand for better solutions is exploding. In fact, the data extraction market is projected to reach about USD 4.9 billion by 2033. This growth is fueled by the sheer volume of digital paperwork we all face and the urgent need for faster, more accurate ways to process it.
Solving this data extraction puzzle unlocks incredible potential. It frees up your team's time for more important work, enables powerful data analytics, and helps your organization act on insights faster. This guide will walk you through the solutions you need, from quick fixes to powerful automation, to finally get a handle on your PDF data.
Getting Quick Wins With Manual Extraction Tricks

Sometimes you just have a single, straightforward PDF to deal with. In those moments, firing up complex automation software can feel like using a sledgehammer to crack a nut. You just need a few tricks up your sleeve to get the job done quickly, without any extra tools.
I've been there countless times—needing to pull product specs from a supplier's catalog or a few key numbers from an invoice. These manual methods are my first line of defense for immediate results.
The go-to move for most people is a simple copy-and-paste. But as anyone who's tried this knows, it often ends in disaster. You highlight a beautiful, clean table in a PDF, paste it into Excel, and… it's a jumbled mess, all crammed into a single column. It looks useless, but don't give up just yet.
This is where a powerful, and honestly overlooked, feature in your spreadsheet software saves the day.
Turning Messy Pastes Into Clean Data
Both Microsoft Excel and Google Sheets have a built-in tool made for this exact problem: Text to Columns. It's designed to take that single, chaotic column of data and intelligently split it into multiple columns using a delimiter you define, like a space, comma, or tab.
Let's walk through a real-world scenario. You've copied a product list from a PDF and pasted it into cell A1 in your spreadsheet.
Here's how I clean it up in seconds:
- First, select the entire column with the pasted data.
- Head over to the Data tab in Excel’s ribbon.
- Click the Text to Columns button. A wizard will pop up.
- Choose "Delimited" and hit Next. This tells Excel you're splitting the data based on a character.
- Now, pick your delimiter. Often, the spaces between columns in a PDF are what you need. Check the "Space" box. The preview window is your best friend here—it shows you exactly how the data will look.
- Click "Finish" and watch the magic happen. Your jumbled text instantly transforms into a structured, usable table.
This simple process is a game-changer if you're just learning how to extract data from pdf files without fancy software.
Here’s a perfect example of this feature in action, cleaning up data copied from a PDF invoice.
Look at that data preview. The once-jumbled line of text is now neatly sorted into Quantity, Description, Unit Price, and Total. It's ready for calculations.
Handling More Complex Formatting
Of course, not every PDF plays nice. You’ll definitely run into formatting headaches that require a bit more finesse.
The key to successful manual extraction is recognizing the pattern in the chaos. I've found that even the messiest data usually has some underlying structure, like consistent spacing or special characters separating entries. Identifying that pattern is half the battle.
Here are a few common issues I run into and how I manage them:
- Multi-Line Entries: If a single product description spills onto two lines in the PDF, it can break your import. After using Text to Columns, you might need to quickly merge these cells manually in Excel.
- Unwanted Characters: Sometimes, extra symbols or currency signs get copied over. The "Find and Replace" function (Ctrl+H) is your best friend for stripping these out of the entire dataset in one go.
- Inconsistent Spacing: If spaces aren't a reliable delimiter, look for another pattern. Can you split the data by a comma or another symbol instead? Text to Columns is flexible enough to handle that.
The broader PDF software market is exploding, projected to grow from USD 1.96 billion in 2024 to USD 4.69 billion by 2031. This isn't just a random statistic; it shows how critical it is for businesses to get data out of documents efficiently. This growth fuels the development of better tools that help us all.
While these manual tips are fantastic for small, one-off tasks, they become tedious and time-consuming with larger volumes. When you find yourself doing this over and over, it's time to look at more powerful solutions. For those bigger jobs, you might want to check out our complete guide on how to convert PDF to Excel for more robust methods.
Automating PDF Extraction With Python

When the endless cycle of copy-pasting data from PDFs starts eating up your day, that's your cue to think about automation. If you're comfortable with a bit of coding, Python offers a remarkably powerful and flexible way to pull data programmatically. We're not just talking about a one-time extraction; you can build a script that processes batches of documents—think weekly reports or monthly invoices—and save yourself a ton of time.
This approach puts you in the driver's seat. You get total control to tailor the logic to the specific layout of your PDFs, handle weird formatting quirks, and even pipe the output directly into your other data analysis workflows. It’s the perfect sweet spot between mind-numbing manual work and investing in specialized software.
Getting Your Python Environment Ready
Before you can start pulling data, you’ll need to set up your environment with the right tools. For working with PDFs, two libraries have become industry standards: PyPDF2 and pdfplumber. You can install both using pip, Python's package manager, by running these commands in your terminal or command prompt:
pip install PyPDF2pip install pdfplumber
So, what’s the difference?
- PyPDF2 is fantastic for basic PDF tasks. I use it for simple text extraction, splitting and merging files, or rotating pages. It's a solid choice when you just need the raw text content from a document.
- pdfplumber is the heavy hitter. Built on top of
PyPDF2, it's specifically designed to understand the geometry of a page, making it my go-to library for accurately extracting tables.
Once you have these installed, you're ready to start scripting.
How to Pull Basic Text From a PDF
Let's start with a common scenario: you just need to grab all the text from a PDF. This is super useful for making document content searchable or for archiving. The logic is pretty simple—you open the file, loop through each page, and collect the text as you go.
Here's a quick and dirty script using PyPDF2 to get the job done:
import PyPDF2
def extract_text_from_pdf(pdf_path):
text = ""
# 'rb' is important – it opens the file in binary read mode
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
num_pages = len(reader.pages)
for page_num in range(num_pages):
page = reader.pages[page_num]
text += page.extract_text()
return text
Here's how you'd use it:
pdf_file = 'your_document.pdf'
all_text = extract_text_from_pdf(pdf_file)
print(all_text)
This little script gives you a great starting point. You could easily tweak it to save the output to a text file. But, let's be honest, most of the time the valuable data is locked inside tables, and for that, we need a more specialized tool.
Pulling Structured Tables With Pdfplumber
Extracting tables is the holy grail of PDF data work, but it's notoriously difficult. While PyPDF2 can pull the text from a table, it loses all the structure—you just get a jumble of words and numbers. This is precisely where pdfplumber shines. It can detect the lines and cell boundaries, letting you extract the data into a clean, structured format like a list of lists.
Imagine you have a report with a crucial summary table on the first page. With pdfplumber, you can zero in on that specific table and pull its contents cleanly.
A huge advantage of
pdfplumberis its visual debugging feature. You can have it generate an image of the PDF page with boxes drawn around the text and tables it detects. This is a lifesaver for troubleshooting why a script isn't grabbing the data you expect.
Here’s a practical example showing how to extract a table and save it as a CSV file—perfect for opening directly in Excel or Google Sheets.
The highlighted code is where the magic happens. It shows pdfplumber opening the PDF, targeting the first page, and using the extract_table() method to grab the data.
This method is incredibly powerful because it preserves the row-and-column structure. If you’re dealing with financial statements, inventory lists, or any kind of tabular report, learning this technique is a game-changer. For a closer look at getting your data into that final, usable format, check out our guide on how to convert PDF to a CSV file.
Just remember, a Python script works best with native, text-based PDFs. If your documents are scanned images, you'll need to add an Optical Character Recognition (OCR) step to your workflow with a library like pytesseract, which is a whole other layer of complexity.
Tackling Complex and Scanned PDFs with AI Tools
While Python scripts are powerful, they have an Achilles' heel. They really shine with native, text-based PDFs that follow a consistent, predictable structure. But what happens when you’re staring at a scanned document? Or a mountain of invoices from different vendors, each with its own quirky layout? This is where manual copy-pasting and even basic scripts hit a wall.
This challenge is precisely where modern AI-powered tools come into play. These specialized platforms are engineered to solve the exact problems that trip up other methods. They don't just "read" text; they understand the context, making them incredibly effective at handling complexity and inconsistency.
The Magic of Combining AI and OCR
The secret sauce is a potent mix of Optical Character Recognition (OCR) and machine learning. First, the OCR engine does the heavy lifting of scanning the document—even if it's just a blurry image—and turns every letter and number into machine-readable text. This step alone transforms a static picture into something a computer can actually work with.
But that's just the start. The AI layer takes it to a whole new level. It analyzes the entire document, pinpointing key data points much like a human would. It learns to recognize patterns, so it can find an "Invoice Number" or "Total Amount" no matter where it’s located on the page. For any business processing a high volume of varied documents, this is a genuine game-changer.
This image shows a simplified flow of how these intelligent systems approach extracting data from a table.
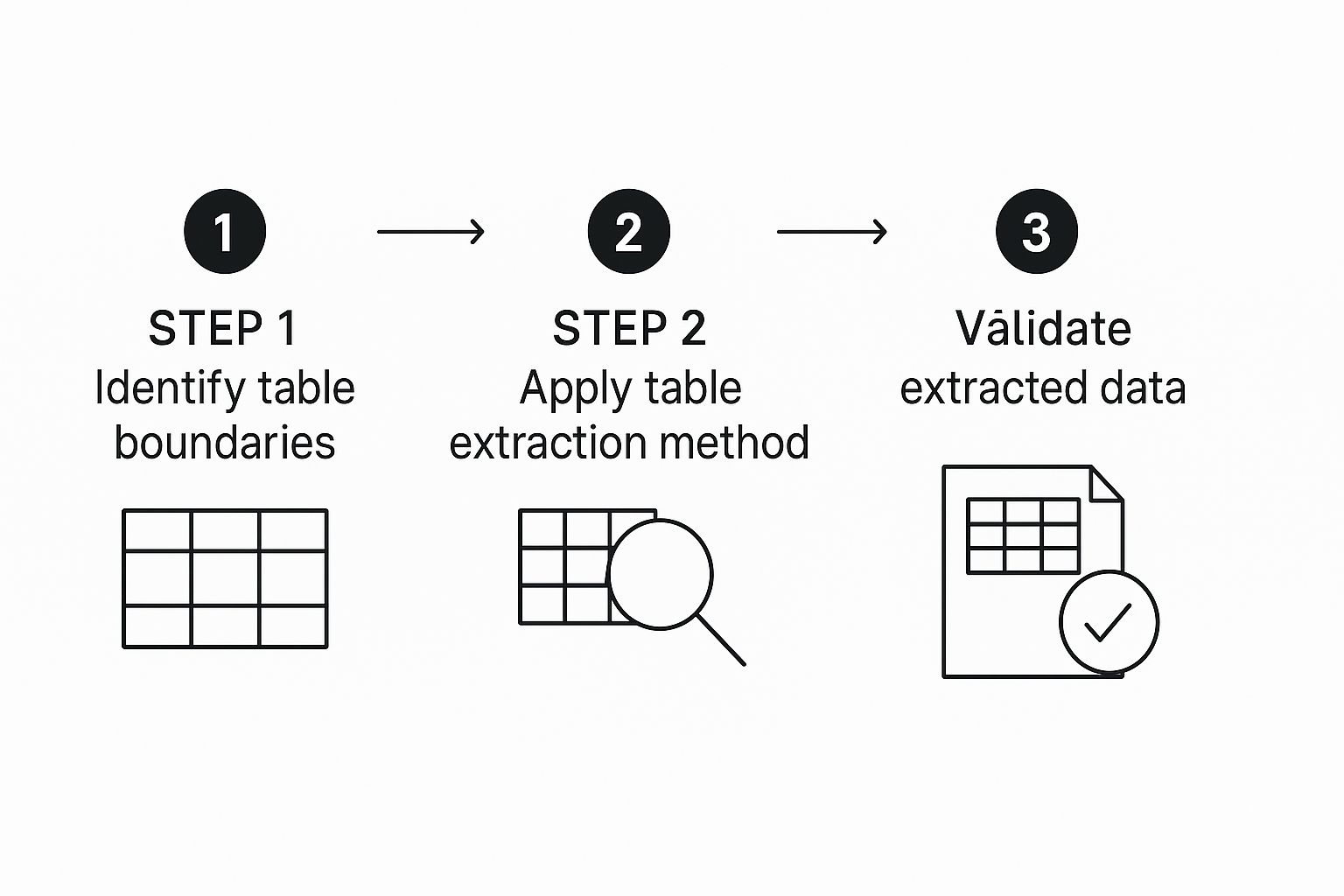
As you can see, the process isn't just about grabbing text. It's about identifying, applying logic, and validating the results, which leads to a much higher degree of accuracy than simple text scraping ever could.
A Real-World Walkthrough with an AI Extractor
Let's put this into a practical scenario. Imagine you're an accountant who needs to process dozens of bank statements from different financial institutions every single month. Manually keying in this data is not only mind-numbingly slow but also ripe for human error.
A tool like Bank Statement Convert PDF is built for this exact job. The process is refreshingly simple and, best of all, requires zero coding.
Here’s what it typically looks like from the user's side:
- Upload Your Document: You just drag and drop your bank statement PDF—whether it's scanned or native—into the web interface.
- Let the AI Do the Work: The platform’s engine immediately gets to work. It uses OCR to digitize the content and its AI model to identify and structure all the transactional data, neatly organizing dates, descriptions, debits, and credits.
- Download Your Data: In just a few moments, you get a perfectly formatted Excel or CSV file. It's ready to be imported directly into your accounting software or used for analysis.
This no-code approach really opens up data extraction to everyone, regardless of their technical skills.
Python Scripts vs. Dedicated Tools: Making the Right Choice
Deciding between a DIY Python script and a dedicated tool often comes down to your specific situation—your resources, the complexity of your documents, and how much time you have.
Here's a table to help you weigh the pros and cons:
Python Libraries vs Dedicated Tools
| Factor | Python Scripts | Dedicated Extraction Tools |
|---|---|---|
| Setup Time | High: Requires environment setup, coding, and extensive testing. | Low: Usually a simple sign-up. You can be up and running in minutes. |
| Accuracy on Scanned PDFs | Moderate to Low: Success depends heavily on the OCR library and script complexity. | High: Built-in, advanced OCR and AI are optimized for scanned documents. |
| Handling Varied Layouts | Difficult: You have to write complex, custom logic for each new layout. | Easy: AI models are trained on millions of documents and handle variety out of the box. |
| Maintenance | Ongoing: You're responsible for maintaining the code and updating libraries. | None: The software provider handles all updates, improvements, and bug fixes. |
Ultimately, choosing a dedicated tool is about valuing your time and the integrity of your data.
The real value of AI tools isn't just extraction; it's the reliability and scalability they provide. When data accuracy is non-negotiable and your document volume is growing, automation becomes a necessity, not a luxury.
The demand for this level of automation is surging, particularly in data-heavy industries. In the healthcare sector, for example, the data extraction market was projected to be worth around USD 3.9 billion by 2025. This growth is fueled by the critical need to accurately pull information from complex PDFs like medical records and reports. You can read more about this trend on the Verified Market Reports website.
So, if you're dealing with scanned documents, inconsistent formats, or you simply need the highest level of accuracy with the least amount of hassle, an AI-powered tool is almost always the most efficient and reliable path forward.
Best Practices For Clean And Reliable Data

Getting data out of a PDF is a great start, but it's really just the first leg of the race. The real win comes from what you do with that data afterward. Let’s be honest: raw, extracted data is almost never clean. It usually needs a good scrub before you can trust it for any serious analysis.
This is where the less exciting but absolutely critical work of data validation and cleaning comes in. I’ve learned the hard way that skipping this step is a recipe for disaster. One misplaced decimal or a date that gets read as text can completely derail a financial report.
So, to get beyond just learning how to extract data from pdf files and move toward building a truly reliable data process, you need a solid game plan. These are the field-tested practices I swear by to make sure the final data is accurate and ready for action.
Validate Data Against The Original Source
Your very first move after any extraction should be a quick spot-check. Never just assume the output is perfect, no matter if you did it by hand, with a script, or using a fancy AI tool. Pull up the original PDF and your new spreadsheet side-by-side.
Pick a few random rows to audit—I usually grab one from the top, one from the middle, and one from the bottom. Meticulously compare the key fields. Are the numbers exactly the same? Did the dates make it over correctly? Is the text identical to what's in the source document?
This simple sanity check can uncover systemic problems right away. You might find your tool keeps confusing the number "1" with the letter "I," or maybe it chokes on a specific currency symbol. Catching this before you dive into analysis will save you a world of frustration.
Create A Repeatable Cleaning Workflow
If you’re pulling data from the same type of PDF over and over, consistency is your best friend. Making one-off fixes every time you run an extraction is slow and a surefire way to make mistakes. The better approach is to build a standardized, repeatable cleaning workflow.
Think of it as your data’s pre-flight checklist. This process should be written down and followed every single time a new batch of documents comes through.
A good workflow usually includes steps like these:
- Zap Duplicates: Find and get rid of any rows that were accidentally pulled twice.
- Standardize Formats: Make sure all dates use the same format (like MM/DD/YYYY), all currency symbols are consistent, and text casing is uniform.
- Handle Missing Values: Have a clear plan for empty cells. Will you fill them with a zero, "N/A," or another placeholder? Your choice depends on what the data will be used for.
- Split Merged Columns: Sometimes, an extraction tool will smoosh two columns of data into one. You need a step to identify and fix this.
Having a structured process like this doesn't just speed things up; it means anyone on your team can handle the task and produce the same high-quality, reliable results.
The ultimate goal is to create a data cleaning process so robust that you can trust the output without having to second-guess it. This trust is the foundation of any data-driven decision.
For specialized documents like financial records, this is even more critical. If you regularly work with bank statements, looking into dedicated bank statement extraction software can give you a pre-built, highly accurate workflow right out of the box.
Anticipate and Fix Common Extraction Errors
After you’ve worked with a few PDFs of the same type, you'll start to notice the same kinds of errors popping up. Being proactive and looking for these common issues is much more efficient than waiting for them to break your spreadsheets.
Here are a few frequent culprits I've learned to watch out for:
- Incorrect Data Types: This is a classic. A column full of numbers gets read as text, which means you can't do any math with it. In Excel, you can usually fix this by selecting the column and changing the format to "Number" or "Currency."
- Misplaced Characters: Pesky characters like dollar signs ($), commas (,), or asterisks (*) can end up where they don't belong, often preventing a cell from being treated as a number. The "Find and Replace" function is your best friend for stripping these out.
- Header and Footer Junk: Extraction tools often grab text from the page header or footer on every single page. This clutters your spreadsheet with repetitive, useless rows that you'll need to filter and delete.
By keeping a mental (or even a physical) checklist of these potential problems, you can quickly scan and repair each new dataset. This small habit makes a huge difference in the quality and reliability of your final work.
Got Questions About PDF Data Extraction? You're Not Alone.
Getting started with PDF data extraction can feel like navigating a maze. It's totally normal to run into questions as you begin, especially since every document presents its own unique puzzle.
I get asked about this stuff all the time. Below, I’ve answered some of the most common questions that pop up. Hopefully, these insights will help you clear any hurdles you encounter.
Can I Pull Data From a Scanned PDF Without Manually Retyping Everything?
Yes, you absolutely can! This is exactly what Optical Character Recognition (OCR) was created for. Think of a scanned PDF as just a picture of text; that's why you can't just copy and paste from it. OCR tools are the bridge that turns that picture back into usable text.
Software like Adobe Acrobat Pro or more specialized AI platforms essentially "read" the image, recognize the shapes of letters and numbers, and convert them into digital, machine-readable text. Modern OCR is remarkably accurate, often handling tricky layouts or slightly blurry scans with ease. It’s the key to working with any non-native PDF.
What's the Best Way to Extract a Table From a PDF?
Honestly, the "best" method really comes down to the kind of PDF you have and how often you need to do it. There's no single silver bullet, so I tend to think about it in a few different ways.
- For a quick, one-time job: If you just need data from a single, simple table, a good old-fashioned copy-paste into Excel might be your fastest route. Once it's in a single column, Excel's "Text to Columns" feature can work wonders to sort it out.
- For repetitive tasks with the same format: This is where a Python script really shines. A library like
pdfplumberis purpose-built for this, allowing you to programmatically find and pull table data with incredible precision from text-based PDFs. Set it up once, and you can run it forever. - For ultimate accuracy across all document types: When you're dealing with scanned documents, really complex tables, or a high volume of files, a dedicated AI tool is the way to go. These platforms are trained to intelligently figure out rows and columns, even when there are no visible lines separating them.
How Do I Deal With PDFs That Have Different Layouts?
Ah, the classic problem. This is a huge headache for anyone processing things like invoices or reports that come from dozens of different companies. Trying to do this manually is a recipe for frustration.
A smartly written Python script can be built with flexible logic. Instead of telling it to grab data from a specific location (like cell B2), you can teach it to find a keyword (like "Invoice Total:") and then extract the number next to it.
But for truly messy, inconsistent layouts, an AI-powered extraction tool is your most powerful ally. These systems use machine learning that's been trained on millions of document variations. They learn to identify what a "total amount" or an "invoice number" is, no matter where it appears on the page. This saves you from the nightmare of coding a new rule for every different layout you receive.
Is It Actually Legal to Extract Data From Any PDF?
This is a critical question, and one you should never ignore. While the technical part of extracting data is one thing, the legality of it depends entirely on where you got the PDF and what you plan to do with the information.
You absolutely must have the legal right to access and use the data. Always be mindful of copyright laws, the document owner's terms of service, and privacy regulations like GDPR. For example, pulling data from a public government report for your own analysis is typically fine. But scraping personal data from PDFs without clear consent? That's almost always illegal and unethical.
The bottom line: make sure you have permission. If you're going to use the data for any commercial reason, be extra cautious. When in doubt, it's better to be safe than sorry and seek legal advice.
Ready to put an end to the soul-crushing grind of manual data entry? Bank Statement Convert PDF gives you a powerful, no-code way to accurately pull data from your most complex financial documents in just a few seconds. Give it a try and see the hours you get back.

